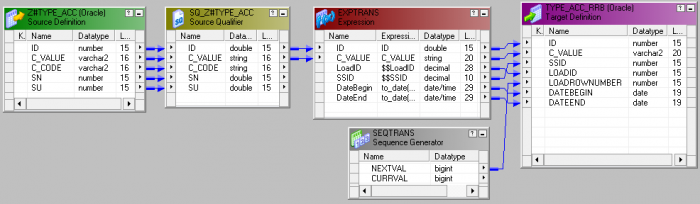
I'm trying to make a simple data loading with an IPC mapping from one Oracle DB to another.
The source table structure is following:
ID NUMBER;
C_VALUE VARCHAR2 (16);
C_CODE VARCHAR2 (16);
SN NUMBER;
SU NUMBER;
The target table structure is following:
ID NUMBER
C_VALUE VARCHAR2 (20)
SSID NUMBER
LOADID NUMBER
LOADROWNUMBER NUMBER
DATEBEGIN DATE
DATEEND DATE
When I'm running the workflow I'm getting the following error:
8340||Error: Target table [TYPE_ACC_RRB] data truncation/overflow error.
When I'm trying to debug my mapping, I'm seing that my input string in the c_value field is presented by the unicode characters and it's length is doubled in bytes.
Does the Informatica count chars of bytes as the length of it's string fields? How to make it see for chars, not for bytes?
What I see from the session log is:
Server Mode: [UNICODE]
Server Code page: [UTF-8 encoding of Unicode]
The session sort order is [Binary].
Source database connection [RBO01] code page: [MS Windows Cyrillic (Slavic)]
Target database connection [STG1] code page: [MS Windows Cyrillic (Slavic)]
My mapping: