I have some files that I would like to consolidate into a single database table. The files have similar but different formats. The files look something like this:
FileOne:
•ColA : string
•ColB : string
•ColC : string
FileTwo:
•ColAA : string
•ColBB : string
•ColCC : string
FileThree:
•Col01 : string
•Col02 : string
•Col03 : string
The destination table looks like this:
TableDestination:
•ColFirst : string
•ColSecond : string
•ColThird : string
I want to develop a mapping that ETLs these three files into this one database, but because the column names are different, it looks like I'll have to develop three different mappings, or three different sources, or three different somethings. The problem is that my example is contrived: I actually have many different files that all have different formats and column names, but the data is all very similar.
I would like to develop a single mapping or workflow that can handle all of this by only adding a table that holds the column mappings. Such a table would look like this based on the sample files and sample table above:
TableMappings:
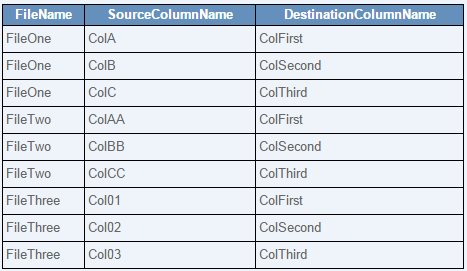
In this way, to edit a column mapping I only have to make an edit this this TableMappings table. I wouldn't have to make any changes at all to the mapping or workflow. Nor would I have to redeploy an application.
What would a mapping or workflow look like that could take advantage of something like this? I assume there'd be a flat file source that takes files from a folder. There would be something in the middle that uses this TableMappings table to map column names. Finally there would be a relational data object that represents my destination database table "TableDestination". I don't know how to put this together though.

